
1. Introduction
In recent times, cryptocurrencies have emerged as a major asset class in the worldwide monetary panorama, attracting substantial curiosity from buyers in search of diversification and different funding alternatives. The decentralized nature and technological improvements underpinning cryptocurrencies, equivalent to Bitcoin and Ethereum, have reshaped conventional monetary paradigms, introducing new dynamics pushed by market sentiment and info dissemination.
By understanding public sentiment for a particular cryptocurrency in advance and monitoring market stress, we are able to predict value actions. Detrimental sentiment in the crypto market typically results in value drops, whereas constructive sentiment tends to drive value will increase. As an illustration, the current worry of potential battle between Israel and Iran triggered a marginal 10% lower in the worth of all cryptocurrencies.
On this context, our research focuses on the comparative evaluation of enormous language fashions (LLMs) and NLP methods in the area of cryptocurrency sentiment evaluation. Particularly, we examine the efficacy of fine-tuned fashions equivalent to GPT-4, BERT, and FinBERT for discerning sentiment from cryptocurrency information articles. By leveraging the capabilities of those subtle language fashions, we intention to discover how successfully they will seize nuanced sentiment patterns, thus contributing to a deeper understanding of sentiment dynamics throughout the cryptocurrency market.
The first goals of this research are twofold: firstly, to judge the efficiency of LLMs and NLP fashions in cryptocurrency sentiment evaluation by means of a comparative classification research, offering insights that may inform funding methods and threat administration practices inside cryptocurrency markets; and secondly, to handle particular analysis inquiries that earlier research haven’t adequately coated.
-
Q1: Among the many fine-tuned fashions of GPT-4, BERT, and FinBERT, which one demonstrates superior predictive capabilities in cryptocurrency information sentiment evaluation and classification?
-
Q2: What’s the influence of fine-tuning LLMs and NLP fashions for particular duties?
2. Literature Evaluate
Cryptocurrency sentiment evaluation entails using subtle NLP fashions to investigate textual information sources like information articles, social media posts, boards, and blogs associated to cryptocurrencies. The first goal is to extract and quantify sentiment—whether or not constructive, unfavourable, or impartial—expressed in these texts to grasp the prevailing market sentiment in the direction of particular cryptocurrencies or the broader market as an entire.
The importance of cryptocurrency sentiment evaluation in monetary markets is underscored by a number of compelling causes:
-
Market sentiment understanding: Cryptocurrency markets are extremely delicate to sentiment influenced by information occasions, social media developments, regulatory developments, and investor perceptions [4]. Sentiment evaluation aids in assessing the prevailing sentiment and temper of market individuals, providing insights into potential market actions.
-
Resolution-making help: Sentiment evaluation performs a pivotal function in guiding funding selections. Merchants and buyers leverage sentiment-driven insights to make knowledgeable selections; constructive sentiment could sign shopping for alternatives, whereas unfavourable sentiment might immediate warning or promote alerts [7,8].
-
Danger administration: Assessing sentiment contributes to managing dangers linked with cryptocurrency investments [9]. Sudden shifts in sentiment in the direction of particular cryptocurrencies might point out potential value volatility or market downturns.
Within the cryptocurrency ecosystem, sentiment evaluation provides distinctive benefits owing to the decentralized and quickly evolving nature of cryptocurrencies. The wealth of on-line information sources, together with social media platforms and cryptocurrency information web sites, renders sentiment evaluation significantly related and useful for comprehending market habits and investor sentiment in this area.
By harnessing sentiment evaluation methods, researchers and market individuals attain deeper insights into the components driving cryptocurrency markets, empowering them to make extra knowledgeable selections based mostly on sentiment-driven intelligence. This underscores the pivotal function of sentiment evaluation in enriching market intelligence and facilitating efficient decision-making throughout the dynamic and risky cryptocurrency panorama.
2.1. NLP in Sentiment Evaluation
NLP is integral to the sector of sentiment evaluation, providing tailor-made methods to successfully extract sentiment from textual information. In sentiment evaluation, NLP strategies are important for discerning the feelings and opinions conveyed by means of language. Among the most generally used methods and purposes inside monetary contexts embody:
-
Sentiment lexicons: Sentiment lexicons are curated dictionaries that includes phrases or phrases annotated with sentiment scores (e.g., constructive, unfavourable, impartial) [7], aiding sentiment evaluation by quantifying sentiment from particular phrase utilization. Broadly used lexicons like SentiWordNet and Vader are foundational sources. In monetary sentiment evaluation, specialised lexicons capturing monetary terminology improve accuracy by accounting for domain-specific expressions and market situations.
-
Deep studying approaches: Deep studying architectures, equivalent to convolutional neural networks (CNNs), recurrent neural networks (RNNs), and bidirectional encoder representations from transformers (BERT) are extensively utilized in sentiment evaluation [10]. CNNs are efficient for characteristic extraction, whereas RNNs excel in sequence modeling [11], and BERT specializes in capturing contextual info from language. Their utility demonstrates outstanding accuracy in deciphering intricate patterns inside textual content. These fashions bear fine-tuning with monetary datasets to raised perceive the nuances of monetary language, thereby enhancing sentiment evaluation in monetary markets. Moreover, integrating domain-specific options by means of NLP methods enhances their effectiveness, enabling the extraction of significant alerts from monetary textual content information [12].
2.2. Earlier Research on Sentiment Evaluation in Cryptocurrencies
Our literature evaluate presents a complete overview of 49 papers on the evolving function of sentiment evaluation in understanding and predicting cryptocurrency market dynamics. The research showcase a various array of methodologies, starting from conventional sentiment evaluation to cutting-edge deep studying fashions, that spotlight the numerous influence of sentiment-driven components on cryptocurrency value actions and investor habits. By leveraging information sources equivalent to social media platforms, information articles, and market indicators, researchers exhibit the potential of sentiment evaluation to supply useful insights for navigating the risky cryptocurrency panorama and making knowledgeable funding selections. Regardless of the progress made, challenges equivalent to bias mitigation in sentiment information and the nuanced interaction between sentiment and elementary market components underscore the continued want for additional exploration and refinement in this burgeoning subject of analysis. By means of modern approaches and sensible purposes, the reviewed research collectively contribute to advancing sentiment evaluation as a strong device for cryptocurrency market evaluation and decision-making.
2.2.1. Conventional Supervised Studying
2.2.2. Deep Studying
2.2.3. Lexicon-Based mostly Sentiment Evaluation
2.2.4. BERT and Transformer Models
2.2.5. Time-Collection Evaluation
2.2.6. Computational Textual content Evaluation
2.2.7. Hybrid Models
2.2.8. Different Strategies
3. Supplies and Strategies
This research initially focuses on using the modern GPT-4 LLM, alongside a parallel comparability with BERT and FinBERT NLP fashions. All of the fashions have demonstrated proficiency in comprehending human textual content. On this proposed strategy, the fashions will bear fine-tuning on a dataset utilizing few-shot studying, and their sentiment evaluation capabilities shall be evaluated by means of direct comparisons earlier than and after fine-tuning.
Within the early levels of our analysis, we rigorously assess GPT-4’s capability to precisely determine sentiments inside a crypto information article. This entails conducting an exhaustive efficiency analysis by evaluating the bottom GPT-4 mannequin with its fine-tuned counterpart. Subsequently, we proceed to fine-tune the BERT and FinBERT fashions for cryptocurrency sentiment evaluation. We evaluate the fine-tuned LLM and NLP fashions, demonstrating how the fine-tuning course of enhances their functionality to successfully handle the complicated challenges of sentiment evaluation with improved precision.
To fulfill this paper’s objectives, a tailor-made analysis methodology was essential, chosen to facilitate information cleansing, characteristic engineering, mannequin implementation, and fine-tuning. Subsequent subsections elaborate on this framework, providing a complete technique for the research.
3.1. Dataset Splitting, Cleansing, and Preprocessing
To make sure the standard and effectiveness of our predictive modeling and fine-tuning procedures, we meticulously ready the dataset by means of a scientific strategy comprising a number of important steps designed to boost its suitability for classification and sentiment evaluation duties.
Initially, we parsed the ‘sentiment’ column, extracting solely the category label from dictionaries like {‘class‘: ‘unfavourable’, ‘polarity’: -0.01, ‘subjectivity’: 0.38}. Following this, we targeted on information preprocessing to boost dataset high quality, particularly eradicating particular characters and pointless white areas to take care of information integrity and coherence. This step was essential to make sure compatibility for modeling functions and forestall undesirable noise that might have an effect on NLP mannequin efficiency.
Moreover, textual content normalization performed an important function in making certain uniformity and standardization of textual content information. Operations included changing accented characters to their base types, making certain constant remedy of phrases with accent variations. Moreover, to attain case-insensitivity, we systematically transformed all textual content to lowercase.
For our few-shot studying research, we randomly chosen 5000 rows from the dataset of 31,037, making certain equal distribution of labels throughout the three sentiment classes.
In NLP duties, dataset division is pivotal for efficient mannequin improvement, refinement, and analysis. Our methodology concerned splitting the dataset into coaching, validation, and check units, facilitating mannequin studying from enter information throughout fine-tuning, tuning hyperparameters for enhanced generalization, and in the end evaluating mannequin efficiency by means of predictions on the check set.
Superb-tuning BERT or its variants (like FinBERT) sometimes requires label encoding because of the nature of the underlying frameworks (like PyTorch and TensorFlow). These frameworks count on numerical labels for classification duties. Though higher-level libraries (equivalent to Hugging Face’s Transformers) permit working with string labels at a extra summary degree, internally, these labels are transformed to numerical values. For instance, when utilizing Hugging Face’s Transformers library, you’ll be able to specify labels as strings in the configuration or throughout dataset preparation, however the framework will encode these labels into integers for processing by the mannequin. For our classification process, we chosen reworking the string sentiment labels into integers utilizing nominal encoding: constructive as 1, unfavourable as 0, and impartial as 2, with out implying any order. Moreover, we employed cross-entropy loss, the default loss perform in BertForSequenceClassification, which is nicely suited to classification duties with nominally encoded labels.
3.2. GPT Immediate Engineering
Our goal was to develop a immediate that seamlessly integrates with varied LLMs, enhancing the accessibility of their outcomes by means of our code. We targeted not solely on the immediate’s content material but in addition on its output formatting. To offer additional readability on the method of deriving the immediate design, we elaborate on a number of key points:
-
Preliminary analysis and understanding: The method started with a radical examination of varied language mannequin architectures, together with however not restricted to GPT-3, GPT-4, LLaMA-2, and others. This concerned understanding their capabilities, limitations, and distinctive options. This foundational analysis ensured that our immediate design can be appropriate and efficient throughout a various vary of fashions.
-
Identification of challenges: We recognized two major challenges in crafting the immediate: (a) creating content material that may be model-agnostic and (b) making certain the accessibility of the output format [55]. The previous required creating a immediate that may very well be understood and responded to by any LLM, no matter its structure. The latter concerned designing an output format that may facilitate ease of use and integration into code, significantly emphasizing JSON formatting for versatility and compatibility.
-
Finalization and validation: After rigorous testing and refinement, we arrived at a finalized immediate that successfully elicited responses in the specified output format. Validation by means of Supply Code 1 demonstrates the immediate’s capability to generate significant responses understandable to all fashions, thus fulfilling our goals of accessibility and compatibility.
| dialog.append({‘function’: ‘system’, ‘content material’: “You’re a crypto knowledgeable.”}) |
| dialog.append({‘function’: ‘consumer’, |
| ‘content material’: ‘Consider the sentiment of the information article. Return your response in JSON format {“sentiment”: |
| “unfavourable”} or {“sentiment”: “impartial”} or {“sentiment”: “constructive”}. Article:n’ + |
| enter[‘text’] + “}) |
3.3. Mannequin Deployment, Superb-Tuning, and Predictive Analysis
As mentioned earlier in this research, we make use of two distinct fashions to handle sentiment evaluation and classification duties throughout the cryptocurrency sector. Whereas earlier analysis has explored cryptocurrency sentiment evaluation utilizing varied algorithms and methods, there’s a important hole in using LLMs for this function. On this research, we now have determined to extensively check the GPT-4, BERT, and FinBERT fashions each earlier than and after fine-tuning. Under, we current an outline of how every mannequin is deployed, showcasing our modern strategy to using them for this particular process.
3.3.1. GPT Mannequin Deployment and Superb-Tuning
Conceptual Background of LLM Superb-Tuning
Superb-tuning an LLM entails taking a pre-trained language mannequin and coaching it additional on a particular dataset to adapt it for a selected process. This course of permits the mannequin to study task-specific patterns and nuances that will not be coated throughout its basic pre-training part.
-
Low-rank adaptation (LoRA): this method reduces the variety of trainable parameters by decomposing the burden matrices into lower-rank matrices, making the coaching course of extra environment friendly.
-
Parameter-efficient fine-tuning (PEFT): PEFT strategies deal with fine-tuning solely a small subset of the mannequin’s parameters, decreasing the computational load and reminiscence utilization.
-
DeepSpeed: an optimization library that facilitates environment friendly large-scale mannequin coaching by enhancing GPU utilization and reminiscence administration.
Superb-Tuning Part
We fine-tuned the gpt-4-0125-preview base mannequin utilizing the official OpenAI API, incorporating the next steps:
-
Knowledge preparation: We generated two JSONL recordsdata for coaching and validation, containing immediate–completion pairs (Supply Code 2). As described in Section 3.1, these pairs have been derived from our coaching and validation CSV recordsdata, which include the textual content material of stories articles and their corresponding sentiment labels.
-
Coaching configuration: the fine-tuning was carried out with the next hyperparameters:
-
Job ID: ft:gpt-4-turbo-0125:private::9Aa7kYOh.
-
Whole tokens: 765,738.
-
Epochs: 3.
-
Batch measurement: 6.
-
Studying price (LR) multiplier: 8.
-
Seed: 65426760.
-
Coaching course of: The mannequin underwent a multi-epoch coaching technique, iteratively refining its understanding and capabilities. The preliminary coaching loss was 0.9778, which progressively decreased to just about 0.1, indicating important enchancment in mannequin efficiency over time.
Sentiment Evaluation and Analysis Part
Following fine-tuning, the mannequin was deployed to carry out sentiment evaluation on a check set of stories articles. The method included the next steps:
-
Prediction technology: The fine-tuned mannequin was tasked with predicting the sentiment of every article in the check set by making calls to the OpenAI API, specifying the ID of the fine-tuned mannequin. Analyzing the textual content material, the mannequin examined the articles and generated sentiment labels based mostly on the patterns discovered throughout fine-tuning, presenting the outcomes in a JSON format.
-
Comparability with unique labels: The expected sentiment labels have been rigorously in contrast in opposition to the unique labels in the dataset. This comparability facilitated a complete evaluation to evaluate the mannequin’s effectiveness in capturing article sentiments and its alignment with human judgments.
-
Integration of outcomes: the outcomes of the sentiment evaluation have been built-in into the test_set.csv file, offering a consolidated view for subsequent comparative analyses.
-
Efficiency metrics: To judge the mannequin’s efficiency, normal metrics equivalent to accuracy, precision, recall, and F1-score have been computed. These metrics offered insights into the mannequin’s capability to generalize and carry out precisely on unseen information.
The identical prediction and analysis process was utilized to the GPT-4 base mannequin utilizing zero-shot coaching. This allowed for a direct comparability between the bottom mannequin and the fine-tuned mannequin, underscoring the need of fine-tuning for particular duties.
| {“messages”: [ |
| {“role”: “system”, “content”: “You are a crypto expert.”}, |
| {“role”: “user”, “content”: “Evaluate the sentiment of the news article.” |
| “Return your response in JSON format {”sentiment”: ”negative”}” |
| “or {”sentiment”: ”neutral”} or {”sentiment”: ”positive”}.” |
| “Article:n …”}, |
| {“role”: “assistant”, “content”: “{”sentiment”:”negative”}”} |
| ]} |
3.3.2. BERT and FinBERT Mannequin Deployment and Superb-Tuning
Coaching Part
-
Knowledge preparation: the dataset, as described in Section 3.1, was ready for our process, ensuing in the creation of three recordsdata: check, prepare, and validation CSV recordsdata.
-
Coaching configuration: each bert-base-uncased and FinBert fashions have been educated with the next hyperparameters:
-
Optimizers: Adam and AdamW.
-
Epochs: 3.
-
Batch measurement: 6.
-
Studying price: 6.
-
Most sequence size: 512.
-
Coaching course of: The coaching process happened in the Google Colab surroundings. Every mannequin underwent three epochs of coaching, with progress monitored utilizing the tqdm library. The coaching concerned backpropagation, optimization, and validation, leveraging an A100 GPU for accelerated computations. Submit-training, the fine-tuned fashions and tokenizers have been saved to a listing in Google Drive for future use.
Sentiment Evaluation and Analysis Part
4. Outcomes
4.1. GPT Base Mannequin Analysis Part
Within the preliminary part of our research, we used the GPT-4 LLM base mannequin, particularly gpt-4-0125-preview, to conduct sentiment evaluation and classification on cryptocurrency information articles. We employed the check set consisting of 1000 articles with the objective of assessing the accuracy of the GPT base mannequin in categorizing every article’s sentiment (constructive, impartial, or unfavourable).
Upon thorough evaluation of the mannequin’s outputs and comparability with the unique user-provided labels, we made a number of notable observations. The gpt-4-0125-preview mannequin exhibited a commendable degree of accuracy, appropriately predicting the sentiment class for 82.9% of the articles. This equates to profitable predictions for 829 out of the 1000 articles in our check dataset. These outcomes exhibit that even the bottom mannequin, with out particular fine-tuning, reveals a major capability to deduce sentiment from content material based mostly on contextual clues.
It is very important spotlight that reaching an 82.9% accuracy price in predictive modeling is sort of excessive, indicating that the mannequin might be confidently utilized to sentiment evaluation and classification duties. Nonetheless, additional enhancements might be achieved by fine-tuning the fashions to raised swimsuit the particular process at hand. This refinement course of can improve their capability to seize and perceive complicated patterns and relationships throughout the information.
4.2. Superb-Tuned Models Analysis Part
Within the subsequent part of our analysis, we targeted on fine-tuning the GPT-4, BERT, and FinBERT fashions utilizing two completely different optimizers. This fine-tuning course of was carried out utilizing a coaching set of 3200 cryptocurrency articles, with the first goal of enhancing the fashions’ efficiency and their capability to investigate cryptocurrency sentiment.
Precision values, indicating the fashions’ capability to precisely classify situations inside every class, range throughout fashions and courses. Curiously, the GPT base and fine-tuned fashions exhibit comparatively greater precision in predicting constructive labels (class 1), whereas each the BERT and FinBERT fashions excel in predicting impartial labels (class 2), suggesting the next tendency for false positives in the category 0 and 1.
The recall values replicate the fashions’ proficiency in appropriately capturing situations of every class. As an illustration, the ft:finbert-adamw mannequin reveals excessive recall for sophistication 2, highlighting its effectiveness in figuring out situations belonging to that class.
The F1-score, hanging a stability between precision and recall for every class, showcases the ft:gpt-4 mannequin’s superior efficiency with the best F1-score for sophistication 1, indicating its balanced precision and recall for that class.
In abstract, whereas every mannequin shows strengths in particular metrics, the fine-tuned GPT-4 mannequin emerges because the standout performer with excessive accuracy, balanced precision and recall, and low imply absolute error, suggesting its superior efficiency throughout a number of analysis standards. However, the selection of mannequin could range relying on particular use instances or priorities, the place different fashions could supply benefits in sure points equivalent to recall for particular courses or precision in explicit eventualities.
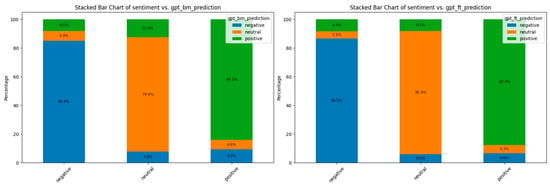
4.3. Assessing Models’ Efficiency and Proximity with Authentic Labels
Armed with these insights, additional optimizations might be pursued by means of changes to boost general mannequin efficiency.
5. Dialogue
In earlier sections, we delved into the methodology and outcomes associated to the predictive efficiency of the GPT-4 LLM, BERT, and FinBERT NLP fashions earlier than and after fine-tuning for cryptocurrency information sentiment evaluation and classification. This part unveils the analysis discoveries and insights gained by the authors regarding the effectiveness of LLMs and NLP fashions as useful instruments for sentiment evaluation in the cryptocurrency area, addressing pertinent analysis inquiries.
5.1. Analysis Findings
Furthermore, each the BERT and FinBERT fashions with the ADAM optimizer practically matched the predictive functionality of a sturdy LLM, differing by solely 3.4% and 2.4%, respectively. This small variation may very well be attributed to variations in their pre-training phases, the place the GPT-4 mannequin had the benefit of publicity to a wider and extra different set of public datasets. This intensive coaching possible facilitated extra complete and focused fine-tuning, granting the GPT mannequin a deeper comprehension of nuanced cryptocurrency themes. Consequently, the GPT mannequin is likely to be higher positioned to provide exact and contextually related responses.
It is very important be aware that every mannequin reveals greater accuracy for particular labels. As an illustration, the fine-tuned GPT-4 mannequin is extra correct in predicting constructive labels, whereas BERT and FinBERT excel in predicting impartial labels. This highlights that every mannequin has its personal strengths and weaknesses, suggesting {that a} hybrid strategy can be more practical in maximizing outcomes in a manufacturing surroundings.
Lastly, it’s crucial to focus on that even with out fine-tuning, the GPT-4 base mannequin achieved 82.9% accuracy. This demonstrates that LLMs, on account of their intensive pre-training with billions of parameters, can carry out duties with excessive accuracy whether or not fine-tuned on a particular dataset or not. Such capabilities might result in the event of zero-shot, easy but correct instruments for non-specialized groups and organizations.
5.2. The Influence of Superb-Tuning
Customizing LLMs and NLP fashions by way of fine-tuning for specialised duties inside domains like finance and cryptocurrency is crucial to optimize their effectiveness in sensible purposes. Models equivalent to OpenAI’s GPT-4 or BERT are initially educated on huge textual content datasets from various sources, which equips them to know and generate human-like textual content throughout varied domains. Nonetheless, fine-tuning these fashions for particular duties like sentiment evaluation considerably boosts their efficiency and relevance in targeted contexts. As an illustration, the FinBERT mannequin, a variant of BERT, is fine-tuned on specialised monetary label and unlabeled information. Furthermore, even after fine-tuning, these fashions can bear additional fine-tuning for particular duties.
Based mostly on the outcomes derived from this research, fine-tuning an LLM or an NLP mannequin on massive and consultant datasets permits it to achieve a deeper comprehension of the nuances and patterns distinctive to sentiment evaluation, equivalent to in the crypto area, resulting in extra correct predictions. This adaptation entails studying to acknowledge crypto-related terminology, grasp context, and extract related options from textual inputs. By means of iterative changes in the fine-tuning course of, utilizing each coaching and validation information, the mannequin turns into more and more proficient at capturing these domain-specific intricacies, ensuing in improved accuracy and different efficiency metrics.
5.3. Exploring the Price and Usability of LLMs and NLP Models
Our analysis revealed that each the GPT and NLP fashions achieved excessive accuracy in the sentiment evaluation of cryptocurrency information articles. Whereas the fine-tuned GPT mannequin confirmed barely greater accuracy in comparison with BERT and FinBERT, you will need to be aware that BERT is an open-source mannequin accessible totally free use in a self-hosted surroundings. However, GPT-4 requires entry by means of the official OpenAI API, which incurs a price.
For stakeholders or buyers in search of correct and rapid predictions, the GPT API, regardless of its value, provides a extra handy and sustainable answer on account of its user-friendly interface. Conversely, for corporations geared up with an AI crew, deploying a self-hosted answer with BERT or comparable NLP fashions could also be a less expensive selection.
Particularly, throughout the cryptocurrency sector, the place costs can fluctuate inside minutes, software program geared up with NLP applied sciences can detect market developments by means of information blogs, Telegram, or socials, offering crypto buyers with info to regulate their methods and doubtlessly maximize earnings. As an illustration, if a worldwide occasion like a battle between two nations is imminent, an investor might depend on the mannequin to investigate consumer feedback on platforms like Telegram and preemptively promote sure cryptocurrencies to keep away from a major drop in their worth. Conversely, buyers might additionally make the most of low-cost cryptocurrencies that, based mostly on crypto alerts, would possibly quickly improve in worth, resulting in substantial good points.
However, it’s prudent to warning buyers about spam feedback or articles intentionally created to stimulate funding. For instance, many articles are written every day speculating that Ethereum might attain $10,000 by 2025. Such articles serve two functions: producing clicks and attractive inexperienced buyers to speculate in the cryptocurrency with the expectation of considerable worth multiplication.
6. Conclusions
In abstract, the combination of LLMs and NLP fashions for cryptocurrency sentiment evaluation represents a strong toolset that enhances funding decision-making in the dynamic cryptocurrency market. This research showcases the efficacy of state-of-the-art fashions like GPT-4 and BERT in precisely decoding and categorizing sentiments extracted from cryptocurrency information articles. The important thing energy of those fashions lies in their capability to seize refined shifts and complexities in market sentiments, enabling buyers to navigate the risky cryptocurrency panorama with higher perception and confidence.
By leveraging superior NLP capabilities, together with few-shot fine-tuning processes, this research highlights the adaptability and robustness of LLMs and NLP fashions in analyzing sentiment information throughout the cryptocurrency area. These findings underscore the transformative potential of superior NLP methods in empowering buyers with actionable insights, enabling them to proactively handle dangers, determine rising developments, and optimize funding methods to maximise returns.
Particularly, the appliance subject of the analysis outcomes extends to cryptocurrency funding and threat administration. By offering a deeper understanding of sentiment dynamics in cryptocurrency markets, this research facilitates a extra knowledgeable and data-driven strategy to cryptocurrency funding, enabling buyers to make well-informed selections based mostly on the real-time sentiment evaluation of stories articles and different related sources.











{kind=link}